

The first wave of LLM-enabled apps used large models running in the cloud. It's a running joke that most AI startups are just a wrapper around the OpenAI API. This naturally involves sending your prompt and context data to a third party API.
This typically doesn't matter too much when you're just generating funny elephant pictures. But if you're building consumer or professional apps, you don't want to leak sensitive and private data. Retrieval-augmented generation (RAG) compounds the problem, by feeding even more data into the model — silently, in the background.
Developers are looking for alternative architectures that can run RAG without leaking private and sensitive data. At ElectricSQL, we're an open source platform for developing local-first software. So we teamed up with the awesome folks at Tauri to dive into the challenge: could we assemble a fully open source stack for running local AI on device with RAG?
This led us on a wild technical journey where we took Postgres, bundled it with pgvector and compiled it to run cross platform inside the Rust backend of a Tauri app. We then compiled llama2 and fastembed into the same Tauri app and built a fully open source, privacy preserving, local AI application running both vector search and RAG.
You can see the result in the videos below and the example code here. Or get yourself a strong coffee and keep reading to dive in.
AI, vector databases and retrieval-augmented generation
Retrieval-augmented generation (RAG) is is the process of adding additional information to inform the generation process of a large language model (LLM).
Typically, a language model generates responses based on its training data. RAG adds an extra step to this process. When the model encounters a query or a topic, it first performs an search to gather relevant information from a database. This data is then fed back into the language model, supplementing its existing knowledge.
This initial retrieval stage is most often performed by querying a vector database using vector embeddings. Vector embeddings are numerical representations of words, phrases, sentences, or entire documents. These embeddings capture the semantic meaning of the text in a multi-dimensional space, where each dimension represents a particular feature or aspect of the text's meaning.
These embeddings can be either generated from a LLM such as GPT-4 or Llama, or from smaller ones that are easier to run on consumer devices.
To perform RAG using a vector database you:
- generate vector embedding for each document or record you want to make searchable
- store embeddings in a vector database (usually in a column or table that's related to the original data)
- generate a vector embedding from the prompt (i.e.: the query or question) provided by the user
- perform a vector similarity search to find the documents or records that are most closely related to the prompt
- feed both the prompt and the text from the retrieved documents as context into a LLM
- the LLM then generates a response
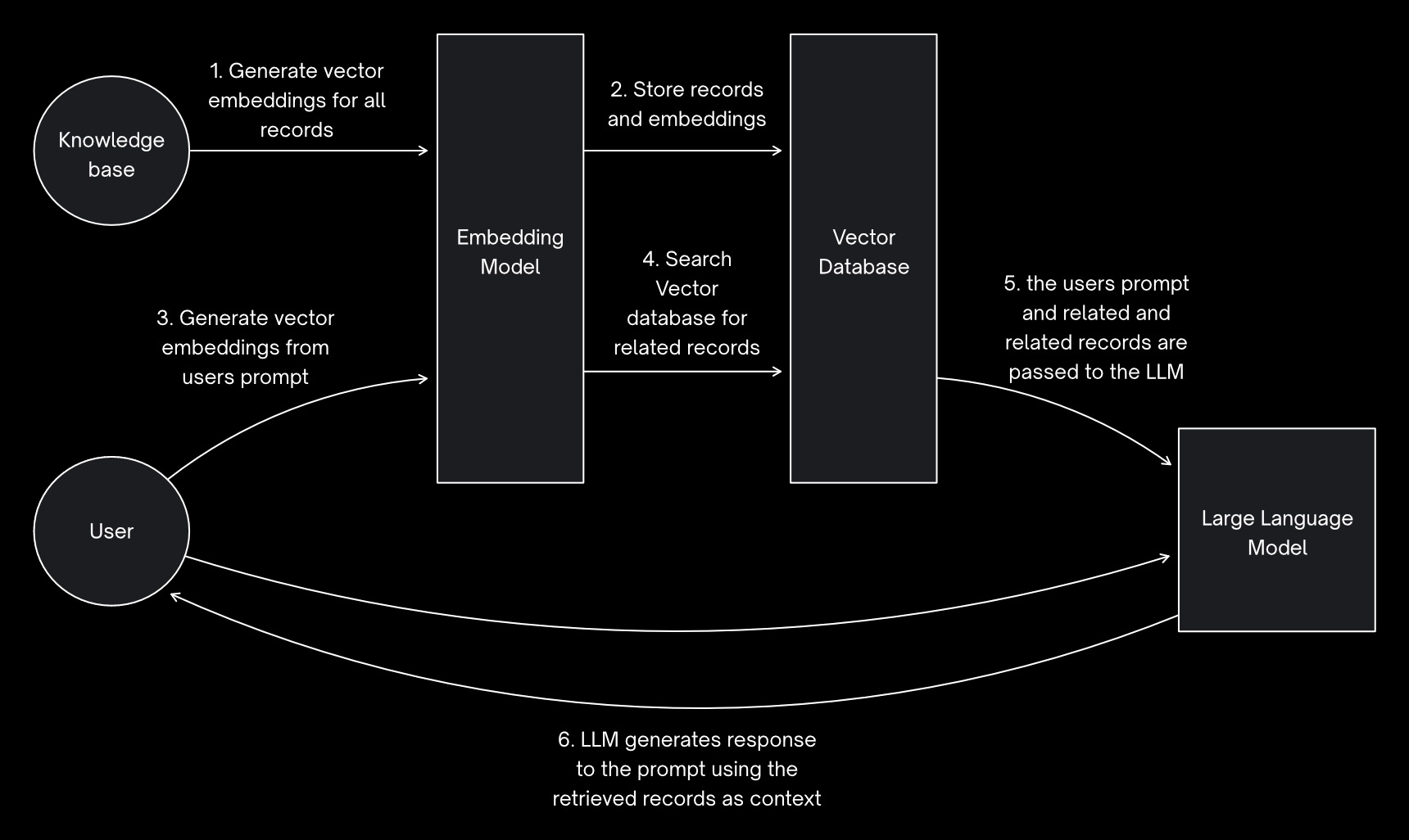
Cloud-based RAG
Cloud-based retrieval-augmented generation has many parts of the pipeline provided by cloud services running behind APIs:
- vector embeddings are generated by a cloud service like the OpenAI embedding API
- the vector database is provided by a cloud service like Pinecone serverless
- the generation is performed by a LLM hosted by a company like OpenAI or Google
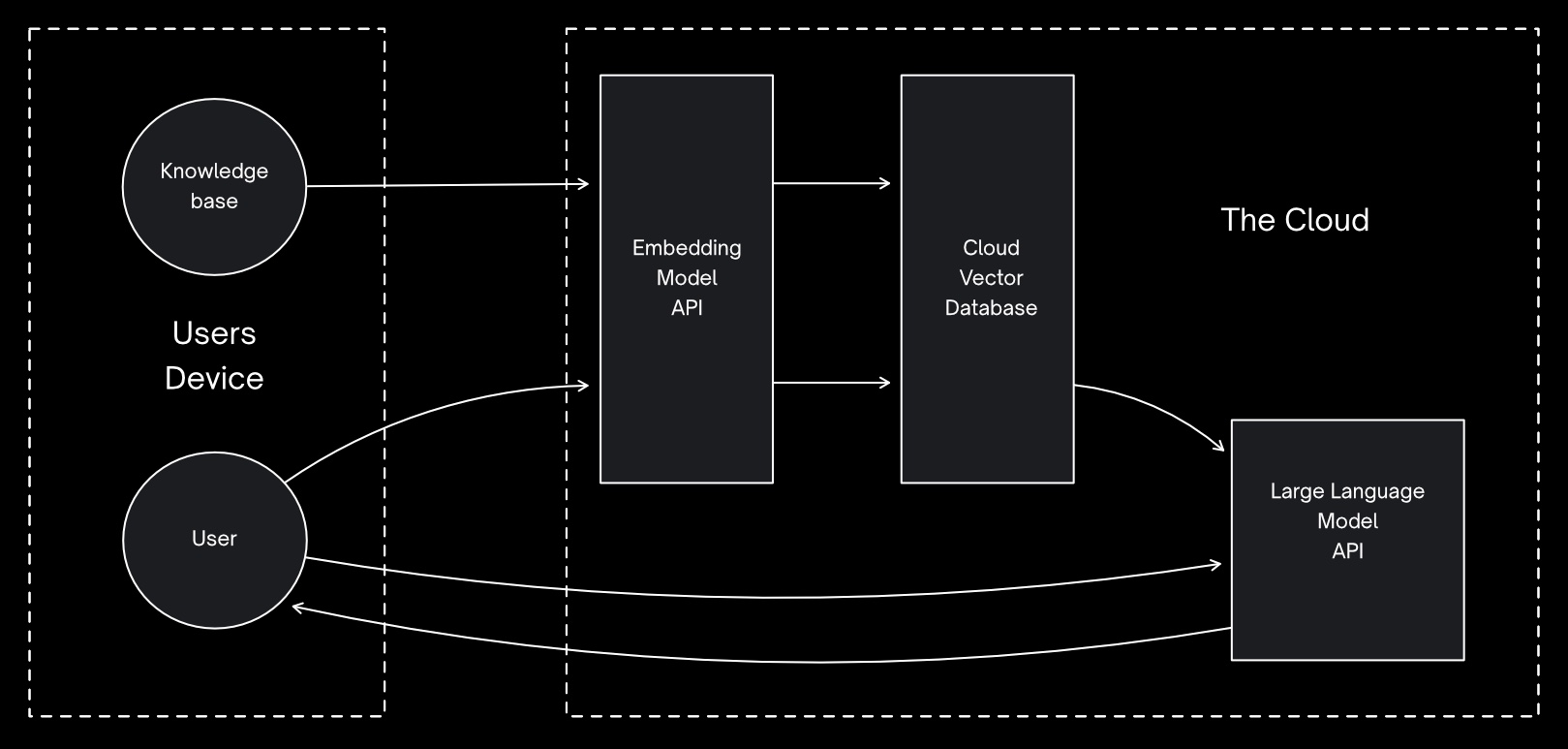
As you can see, this sends both your prompt/query data and information retrieved from your knowledge base to multiple APIs in the cloud.
Local-first RAG
As an alternative, the ideal local-first AI architecture for RAG would be:
- a local, on-device, vector embedding model
- a local vector database, ideally integrated into your main on-device datastore
- a local language model for generation text (or other multi-modal)
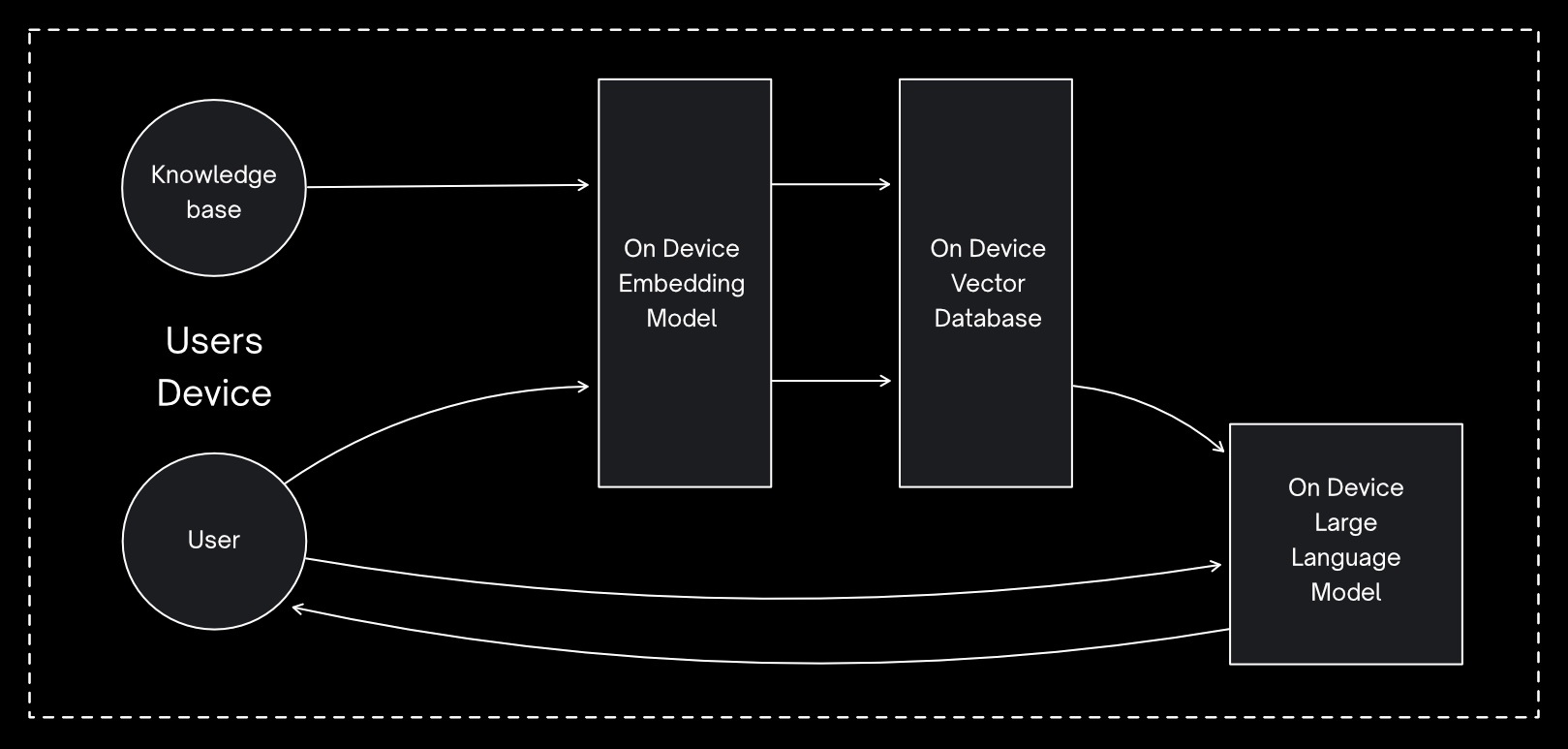
This is the architecture we were able to get to with this project. However, it's worth noting that, on lower-powered devices, such as less powerful mobile phones, it may not be possible to run the LLM locally due to the resources required, so it's also worth considering a hybrid approach.
Hybrid RAG
As the embedding models are significantly smaller, it is possible to have a hybrid model where the embedding model and vector database are on the user’s device, whereas the LLM is provided by a cloud API.
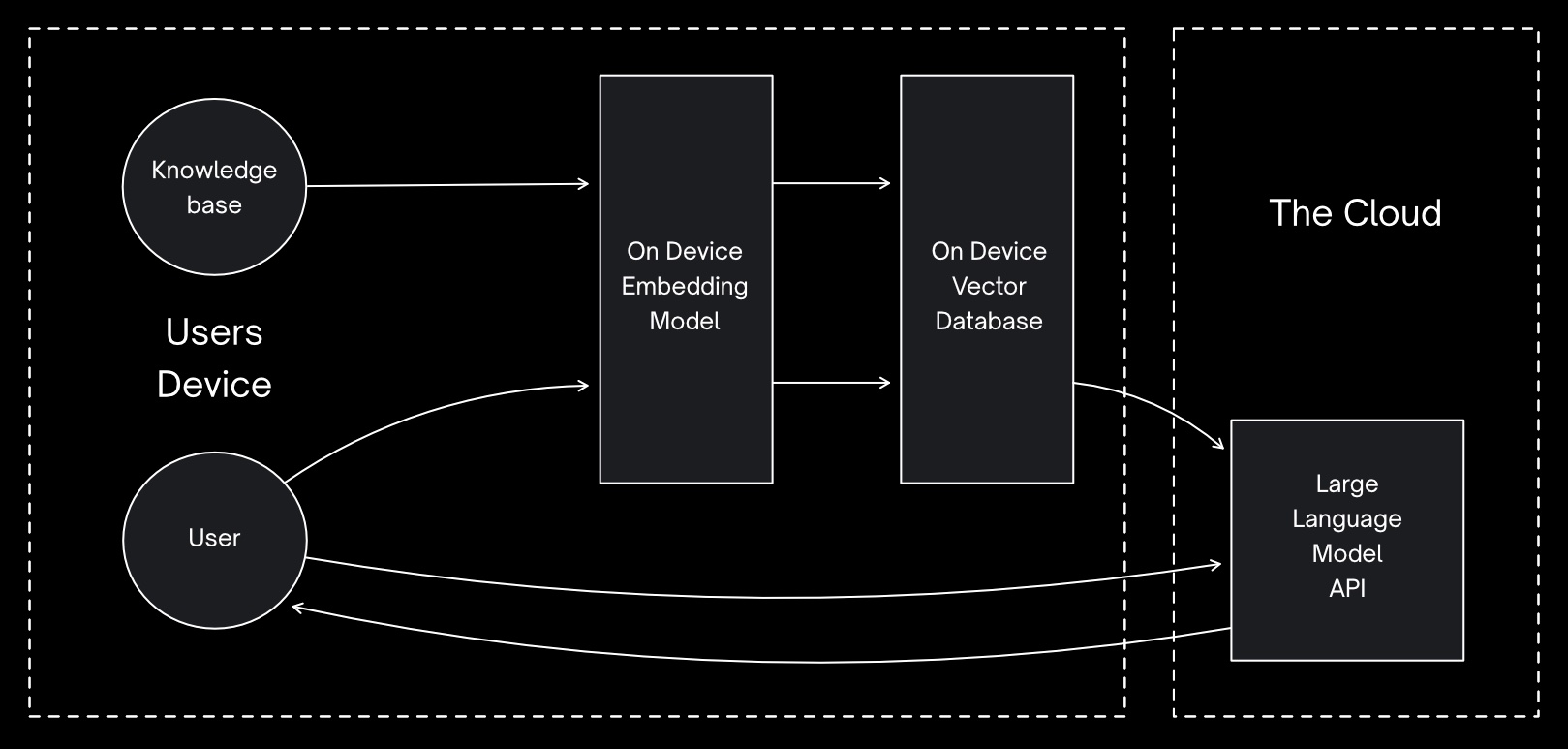
Although this is the route that would be required to perform text generation on some mobile devices at this time, models are getting smaller and more efficient all the time. We expect that the ideal local-first AI architecture will be viable very soon on the majority of mobile devices.
Local AI with ElectricSQL and Tauri
As above, our objective was to assemble a fully open source stack for running local AI on device with RAG. Our stretch goals were also to:
- integrate the vector search and embeddings into the main local datastore
- be able to sync data and embeddings in realtime, between the cloud and local apps and between multiple users and devices
We're a Postgres based system, so when we looked at the options for vector search that integrated into the main datastore, the obvious starting point was pgvector, an open source vector search extension integrated directly into Postgres.
However, the primary ElectricSQL architecture is to sync between Postgres in the cloud and SQLite on the local device. So one approach we could see is to sync embeddings between pgvector in Postgres and sqlite-vss in SQLite. This is another experiment we're keen to do but we were intrigued by another possibility.
What if we could run Postgres with pgvector inside the local app?
Postgres inside Tauri
There have been a number of experiments to compile Postgres for WASM to run in the browser, such as wasm.supabase.com. Unfortunately, none of these are really ready for production use, as the WASM builds are very big (~32MB) and they don't provide basic features like persistence. So, instead, we thought, what if we could compile Postgres into the backend of a Tauri app?
Tauri is an app packaging system for building desktop and mobile apps. It has a unique architecture where the front-end of your app is a standard WebView, using whichever browser is already installed on your system. And the backend of your local app is a Rust environment. Now Rust can import and run native code very well. So surely we could compile Postgres to run in the Rust environment. That would then allow us to run pgvector on device and use the bundled Postgres as the main local datastore.
The process of integrating Electric with Postgres on the client involved several steps.
First we needed to make the ElectricSQL client work with Postgres. The main implementation expected to be talking to SQLite, so we needed to adjust a number of queries and triggers to use the right SQL dialect and database features. To do this, we forked our client and created a new node-postgres driver. Then we iterated in a Node environment until Electric worked against both SQLite and Postgres.
Having updated the Electric client to work with Postgres, we then created a new driver for integrating with Postgres from within the Tauri webview. This involved working on both sides of the Tauri native bridge:
- creating a TypeScript sqlx driver for Electric on the webview side
- developing a Rust adapter to interface with
sqlx, a Rust library for SQL database communication
These components communicated via Tauri's invoke and listen APIs.
To facilitate development, we embedded a psql console in the app using xterm.js, a JavaScript terminal emulator within the Tauri webview. Finally, we made a few minor adjustments to our Linearlite example to get it running on this new stack.
Building local vector search with Tauri and pgvector
After establishing the foundation, we focused on integrating AI features into Linearlite, starting with vector search. This enabled semantic similarity searches for issues and was a prerequisite for developing a RAG workflow.
The first task, which was one of the most challenging parts of the project, was to find a way to build and bundle pgvector in a way that could be packaged in the Tauri app distribution. pgvector is a Postgres extension that adds vector types to the database, as well as providing vector similarity search functions, and indexing of vector columns. It has become a market leader and standard part of many AI stacks.
After much trial and error we found a route that worked: This involved fetching pre-compiled postgres binaries from maven for embedding in the app, along with a full postgres distribution from enterprisedb, which was used for building pgvector for packaging with the embedded postgres.
We chose qdrant's fastembed for local vector embedding generation, offering multiple bindings to popular text embedding models. Using Tauri's invoke API, we made a method available to the TypeScript webview code that generates vector embeddings from text.
We updated the Linearlite database schema to have a vector embedding column for each issue. When a user creates a new issue, we call fastembed to generate an embedding (using the bge-base-en model) to save to the database alongside the issue.
Finally, we updated the search feature to have a vector search option. When the user selects this, their query is converted to an embedding using the exact same api as that used to generate the embeddings for issues. We then perform a vector similar search using pgvector for issues that are closely related to the query.
Enabling local RAG with Ollama, llama2 and Tauri
The final phase involved completing the RAG workflow with a "chat with your issue tracker" UI. The key component was a locally executable LLM, interfaced with the TypeScript frontend. Ollama, a Go wrapper for llama.cpp (a C++ implementation of model inference) and LLMs like llama2, provided the solution. We utilised the ollama-rs crate for integration and chose the 7b version of llama2 for this project.
Using Tauri's invoke and listen APIs, we built a front-end API to Ollama. This allowed sending a chat-start message and streaming the response from Ollama as it generated each token.
The Chat UI's construction was straightforward and completed the RAG workflow:
- when a user enters their prompt, we vectorise the prompt using the API we built for vectorising a search query
- we then perform a vector similarity search for issues that most closely match the prompt provided
- the text from these issues is then concatenated and provided, along with the prompt, to Ollama as context for the generated response
- Ollama generates responses token-by-token, which are streamed to the front-end webview and concatenated
- the response is parsed using react-markdown, rendering rich text with any markdown formatting used by the LLM
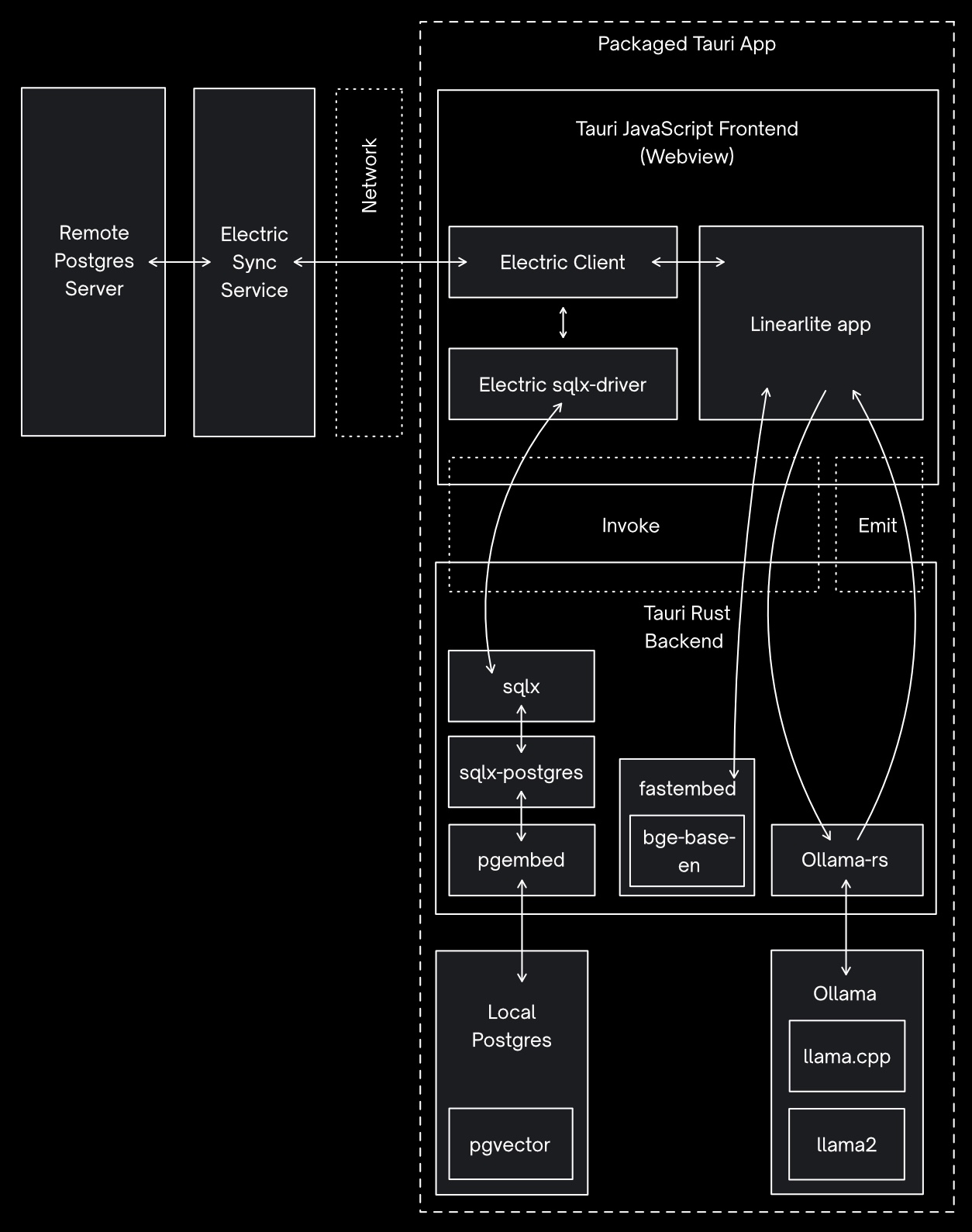
Architecture of the app
The final full architecture diagram of the project is shown here:
Try it out yourself
- Check out the code for this demo on GitHub here
- You can download the pre-built app for macOS
Next steps
There's more to do to productionise this demo and integrate into the primary ElectricSQL stack. We also want to dive into the parallel route with the sqlite-vss in the browser. If you're interested in getting involved, building a local AI app or collaborating on local AI development, let us know on Discord.
Tauri is also expanding to cover more deployment targets, including mobile apps, so we'll look at compiling for those too. Keep an eye on the developments with the Tauri project via their Discord here.